-
[n214] Logistic RegressionAI 부트캠프 2021. 10. 21. 15:46
로지스틱 회귀는 이름은 회귀 이지만 분류문제를 해결한다.
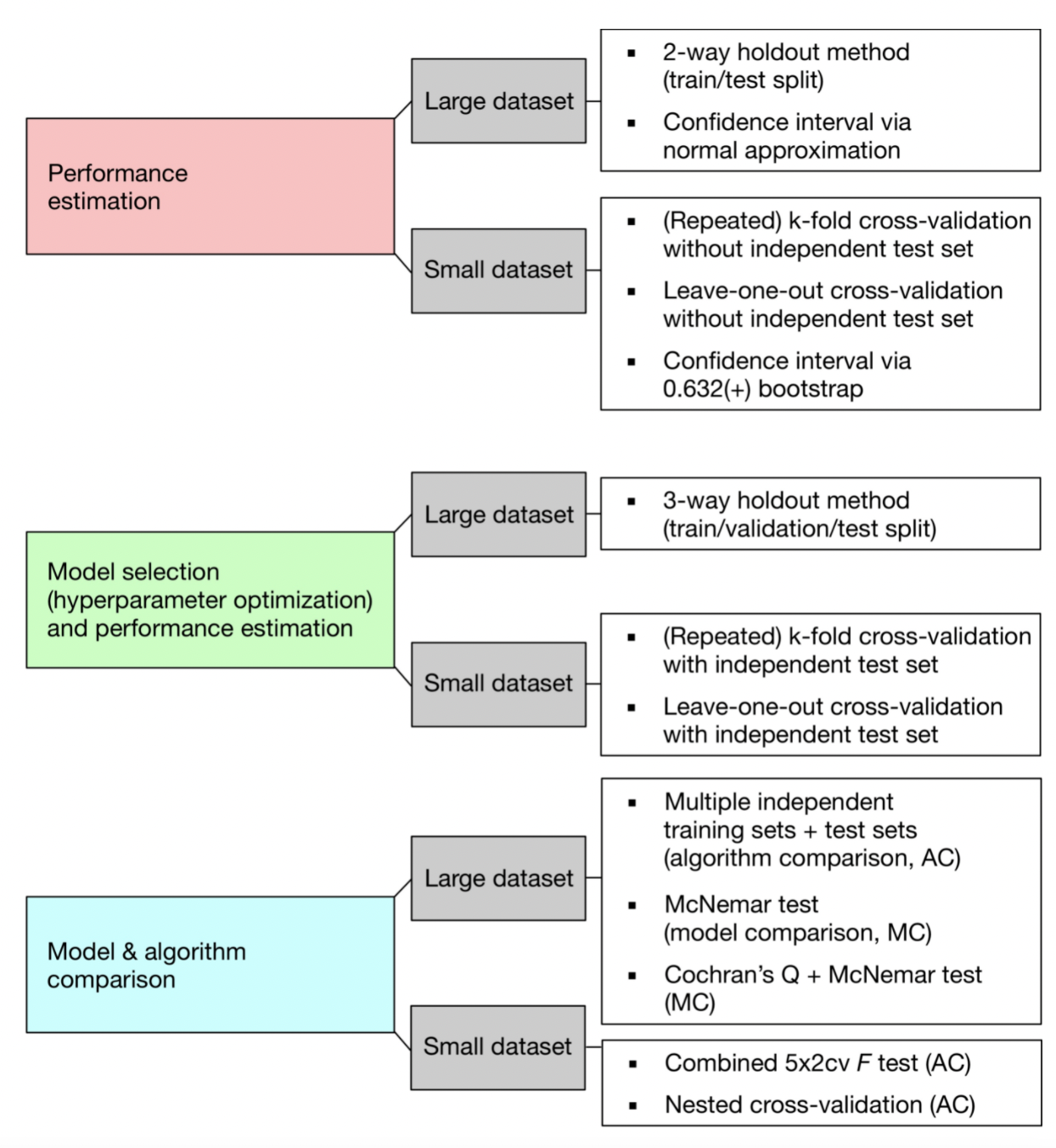
훈련/검증/테스트 세트로 나누는 것은 머신러닝 모델 학습에서 매우 중요.
- 훈련데이터는 모델을 학습 하는데 사용한다. (즉, fit)
- 검증데이터는 모델 학습이 잘 되었는지 판단하기 위해서 사용한다. 이 때 검증 데이터 대신에 테스트 데이터를 사용하면 안된다.
- 마지막에 최종 모델을 평가 하기 위해서 테스트 데이터를 사용한다. 테스트 데이터는 단 한번만 사용하는 것을 주의해야 한다.
- 데이터가 많을 경우, 전체 데이터를 훈련/검증/테스트 세트로 나누면 되지만, 데이터 수가 적은 경우에는 보완하기 위해 K-fold 교차 검증을 사용한다.
모델 검증
분류 문제 (Classification)
- 회귀문제에서는 보통 타겟의 평균값(Mean)을 기준모델로 사용한다.
- 분류문제에서는 보통 타겟 변수에서 가장 빈도가 높은 경우를 기준모델로 설정한다.
- 시계열(time-series) 데이터는 절대 랜덤으로 섞으면 안된다. 미래를 기준으로 과거를 추측하는 경우가 발생한다. 그러므로 시계열 데이터에서 기준 모델은 이전 시간의 데이터이다.
- 분류 문제에서 사용하는 평가지표는 보통 정확도 (Accuracy)이다.
로지스틱 회귀
분류 문제인데, 옵션이 5가지이면 각 각 20%의 확률이므로 정확도가 떨어지게 된다. 그래서 분류가 아닌 회귀를 사용한다.
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘이다. 즉, 로지스틱 회귀는 분류에 사용된다. 다른 선형 회귀와는 다르게 선형 함수의 회귀 최적선을 찾는 것이 아니라, 시그모이드 함수 최적선을 찾고 이 함수의 반환 값을 확률로 간주해 확률에 따라 분류를 결정 한다.

특성 변수를 시그모이드 함수 형태로 표현한다. x값이 ∞로 가면 y는 1에 가까워 지고, -∞이면 y는 0에 가까워진다. 로지스틱 회귀는 0과 1을 예측하기 때문에 단순 회귀식은 의미가 없다.

관측치가 특정 클래스에 속할 확률값으로 계산된다. 예를 들어, 분류문제에서는 확률값이 정해진 기준값보다 크면 1, 아니면 0이라고 예측한다.
로지스틱 회귀는 가볍고 빠르며, 이진 분류 예측 성능도 뛰어나다. 로지스틱 회귀를 이진 분류의 기본 모델로 사용하는 경우가 많다. 또한 로지스틱 회귀는 희소한 데이터 세트 분류에도 뛰어난 성능을 보여서 텍스트 분류에서도 자주 사용된다.
사이킷런은 LogisticRegression 클래스로 로지스틱 회귀를 구현한다. 주요 하이퍼 파라미터로 penalty와 C가 있다. penalty는 규제의 유형 (l1, l2)를 뜻하며 c는 규제 강도를 조절하는 alpha 값의 역수이다. c=1/alpha. 즉, c 값이 작을수록 규제 강도가 크다.
Logistic Transformation
로지스틱 회귀의 계수를 쉽게 해석하기 위해 오즈(Odds)를 사용하여 선형 결합 형태로 변환한 뒤 해석을 한다. 오즈는 실패확률:성공확률 에서 성공확률 비를 뜻한다. 즉, odds=4라면 실패확률보다 성공확률이 4배 더 크다는 의미이다.
이 오즈를 이용하여 로그 변환을 한 것이 로짓 변환(Logit Transformation)이다. 로짓 변환을 통해 회귀 계수를 쉽게 해석할 수 있다. 즉, Feature x값이 증가할 수록 로짓(ln(odds)가 어떻게 변하는가를 해석할 수 있다.
Odds(p) = p / (1-p)
여기서 로짓은 -∞ ~ +∞ 범위를 가진다.

데이터 전처리를 할 때 다음과 같은 데이터 변환이 수행되어야 한다.
- OneHotEncoder : 카테고리 데이터의 경우
- SimpleImputer : 결측치(missing value)가 있는 경우
- StandardScaler : 특성들의 척도를 맞추기 위해 표준정규분포로 표준화하는(평균=0, 표준편차=1) 경우
훈련/검증/테스트 세트로 데이터 나누기
from sklearn.model_selection import train_test_split # 타겟 변수로 나누기. 캐글에서 cardio가 target임을 확인 할 수 있다. target = 'cardio' y = df[target] X = df.drop(target, axis=1) # 훈련/테스트용으로 분리하기 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2) # 훈련세트를 훈련/검증용으로 분리하기 X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=2)위와 같이, 훈련/테스트 데이터로 나눈 뒤, 훈련 데이터를 다시 훈련/검증용으로 나눈다.
로지스틱 회귀 모델 구현
1. category_encoders를 이용하여 gender 특성을 One-hot encoding 한다.
!pip install category_encoders from category_encoders import OneHotEncoder encoder = OneHotEncoder(use_cat_names=True, cols='gender') # 훈련용, 검증용 데이터에 원핫코딩 X_train_encoded = encoder.fit_transform(X_train) X_val_encoded = encoder.transform(X_val)2. 인코딩한 데이터를 표준화한다
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train_encoded) X_val_scaled = scaler.transform(X_val_encoded) # 평균 0, 표준편차 1로 표준화가 되었는지 확인 X_train_scaled.T[0].mean(), X_train_scaled.T[0].std()(-1.3390900075507426e-16, 1.0)
3. 로지스틱 모델 구현
model = LogisticRegression(random_state=1) model.fit(X_train_scaled, y_train) y_pred = model.predict(X_val_scaled) accuracy_score(y_val, y_pred)검증 데이터의 정확도가 다음과 같다. 0.723383351196856
평가지표를 위해 정확도(Accuracy) accuracy_score 를 사용한 것을 볼 수 있다. 분류에서 사용하는 평가지표는 정확도 있다. 회귀와 분류에서는 사용하는 평가 지표가 각 각 다르다.
분류에서는 accruacy, roc_auc 등을 사용할 수 있고, 회귀에서는 MAE, MSE, R2_score 등을 사용할 수 있다.
3.3. Metrics and scoring: quantifying the quality of predictions
There are 3 different APIs for evaluating the quality of a model’s predictions: Estimator score method: Estimators have a score method providing a default evaluation criterion for the problem they ...
scikit-learn.org
'AI 부트캠프' 카테고리의 다른 글
[Section3] Summary (0) 2021.12.04 [회고] 지금의 간절함으로 이루고자 하는 것들. (0) 2021.11.21 [n213] Ridge Regression (0) 2021.10.20 [n211] Simple Regression (0) 2021.10.18 [프로젝트] 게임 설계를 위한 데이터 분석 (0) 2021.10.13