-
[상권 정보 분석] 전처리 과정데이터 분석 2021. 9. 13. 20:29
데이터 전처리 기본 설정
라이브러리 import 및 폰트 설정
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt# 한글폰트를 설정. 설정 안하면 한글이 깨져서 나온다. # Mac plt.rc("font", family="AppleGothic") plt.rc("axes", unicode_minus=False)# 레티나 디스플레이로 폰트가 선명하게 표시. from IPython.display import set_matplotlib_formats set_matplotlib_formats("retina")데이터 로드
# 파일을 로드한다. df = pd.read_csv("data/상가업소정보_201912_01.csv", sep='|')데이터 출처 : 공공데이터포털 소상공인 상권정보 상가업소 데이터
# 모든 컬럼을 보기 위해 max_columns 의 수를 columns 개수로 설정. pd.options.display.max_columns = 39인덱스 정보 보기
# 인덱스 정보 추출 df.index결측치 확인
# true가 결측치 df.isnull()
# 결측치 값을 시각화하자. n = df.isnull().sum() n.plot.bar()
missingno로 결측치 시각화
conda install -c conda-forge missingnoimport missingno as msno msno.matrix(df)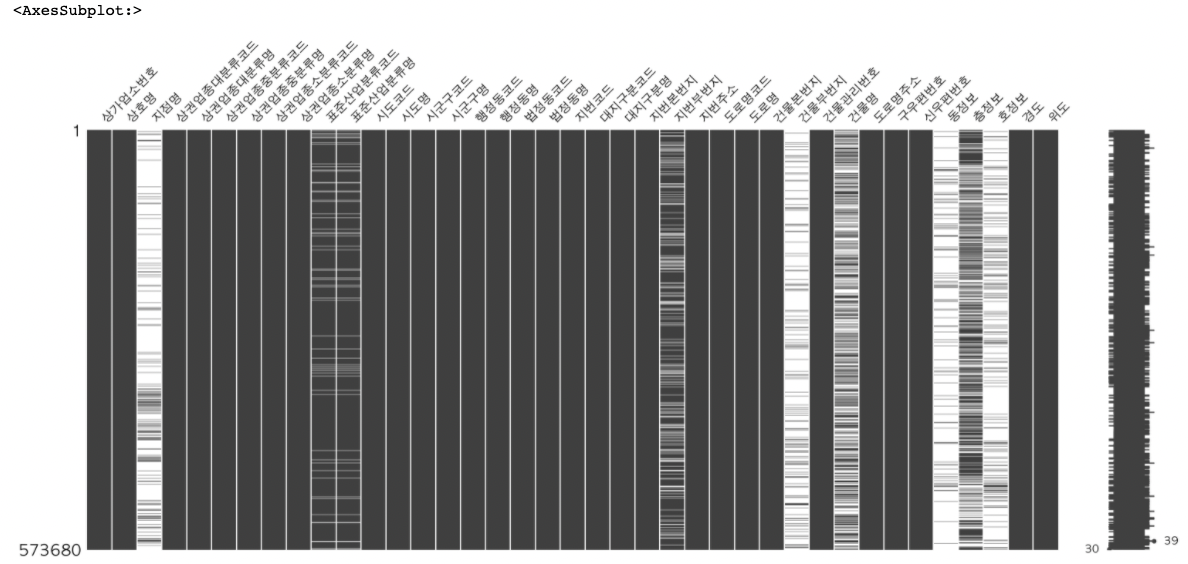
# heatmap으로 표현 msno.heatmap(df)
사용하지 않는 컬럼 제거하기
결측치가 많은 컬럼 제거
not_use = n.sort_values(ascending=False).head(9) not_use_col = not_use.index not_use_col
사용하지 않는 컬럼 제거하기
# 컬럼명을 cols 라는 변수에 입력. cols = df.columns cols
# 컬럼명에 "코드", "번호"가 있지만 이번 분석에서는 사용하지 않기 때문에 # 해당되는 컬럼만 찾아와서 cols_code 라는 변수에 담습니다. cols_code = cols[cols.str.contains("코드|번호")] cols_code
# "코드", "번호" 가 들어가는 컬럼명만 drop으로 데이터프레임에서 제거합니다. # 제거 전 후에 shape를 통해 컬럼이 삭제되었는지 확인합니다. print(df.shape) df = df.drop(cols_code, axis=1) print(df.shape)'데이터 분석' 카테고리의 다른 글
[상권 정보 분석] Folium으로 지도 시각화하기 (0) 2021.09.15 [상권 정보 분석] 기술 통계 분석 (0) 2021.09.14 [데이터 시각화] 히트맵 및 swarmplot (0) 2021.09.12 [데이터전처리] 컬럼이 다른 데이터셋 병합하기 (0) 2021.09.12 [판다스&Seaborn] 데이터 시각화 (line, bar, relplot, catplot, violinplot, boxplot) (0) 2021.09.12