-
[n423] RNN, LSTMAI 부트캠프 2021. 12. 28. 09:17
언어 모델 (Language Model)
언어 모델이란 단어 sequence에서 각 단어의 확률을 계산하는 모델이다. 예를 들어, Word2Vect, CBoW 모두 언어 모델 예시이다.
RNN (Recurrent Neural Network, 순환 신경망)
순환 신경망(RNN)은 연속형 데이터를 처리하기 위한 신경망이다.
연속형 데이터 (Sequential Data)는 순서에 따라서 단어의 의미가 달라지는 데이터이다.


위와 같이 같은 단어 'google'을 어디서 동사로 쓰는지 명사로 쓰는지 추론하는 과정을 모델링한 것이 RNN이다.
아래와 같이 한 문장의 단어를 각 각 x값으로 입력한 뒤, 가중치와 연산을 한 뒤 y값으로 반환한다. 또한 그 전에 계산했던 값이 가중치로 업데이트 된다. (Whh와 Wxh 모두 가중치이며, Whh라고 쓰여있는 것들 모두 서로 같은 값. Wxh와 b도 마찬가지)

소프트맥스에 들어가는 인풋을 보통 logit이라고 한다. 즉, y1=logit1, y2=logi2와 같다. 소프트맥스의 아웃풋은 보통 prediction이라고 하며 이 pred 값을 target값과 비교하여 그 손실을 최소화 해야 한다.


현재 state 값 RNN은 기울기 소실 (Vanishing Gradient)로 인해 장기 의존성 (Long-term Dependency) 문제가 발생한다. 이를 개선하기 위한 방법이 LSTM, GRU(Gated Recurrent Unit)이다.
다양한 형태의 RNN

- one-to-one : 벡터 한개가 들어오면 한 개의 벡터를 반환한다.
- one-to-many : 벡터 한개가 들어오면 sequenctial 벡터를 반환한다. 예를 들어 이미지 캡셔닝(Image captioning)에 사용한다.
- many-to-one : Sequential 벡터가 들어오면 한 개의 벡터를 반환한다. 예를 들어, 문장의 긍정/부정을 분류하는 감성 분석(Sentiment analysis)에 사용.
- many-to-many(1) : 두 가지 경우로 나눌 수 있다. Sequential 벡터를 입력을 모두 받았을 때 출력하는 경우와 받자 마자 출력을 내는 경우로 나뉜다. 전자의 경우 Seq2Seq 구조이며 기계 번역에서 사용된다. 후자의 경우 비디오를 프레임별로 분류하는 경우에 사용한다.
RNN의 장단점
- 장점 : 모델이 간단하다. 이론상으로는 어떤 길이의 sequential 데이터가 들어와도 처리할 수 있다.
- 단점 : 벡터가 순차적으로 입력된다. 즉 벡터가 들어올 때까지 기다려야한다. 즉, 오래걸린다. (GPU 연산의 병렬화를 불가능하게 해서 GPU의 이점을 사용 못한다). 긴 문장(sequence)를 처리할 때 앞쪽에 입력된 단어의 의미가 사라진다.
LSTM (Long Short Term Memory, 장단기 기억망)
Gradient Vanishing
새로운 가중치 = 기존 가중치 - ( learning_rate * dE/dW )
Gradient Vanishing이란 dE/dW값이 0에 가까워져서 결국 새로운 가중치와 기존 가중치가 거의 차이가 없는 현상을 뜻한다.
Gradient Exploding
dE/dW 값이 지나치게 커져서 새로운 가중치의 값이 매우 커지는 현상을 뜻한다. 학습이 안정적이지 못하다.
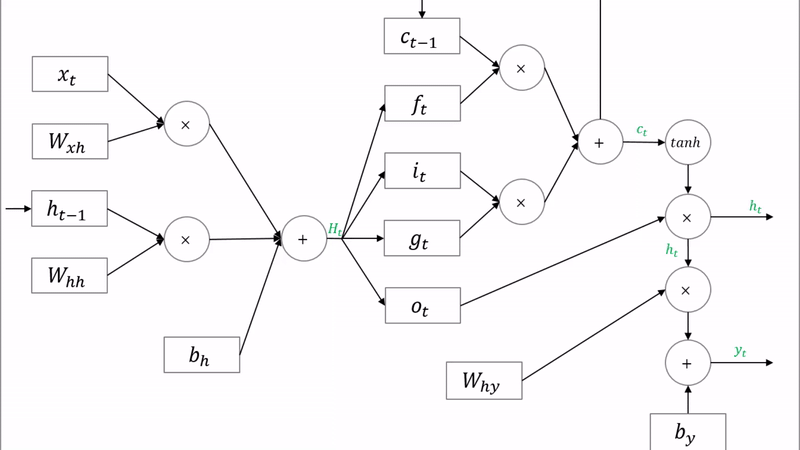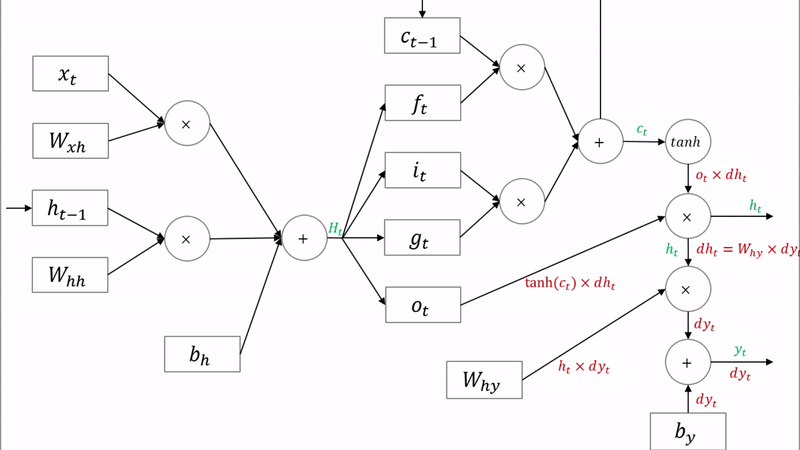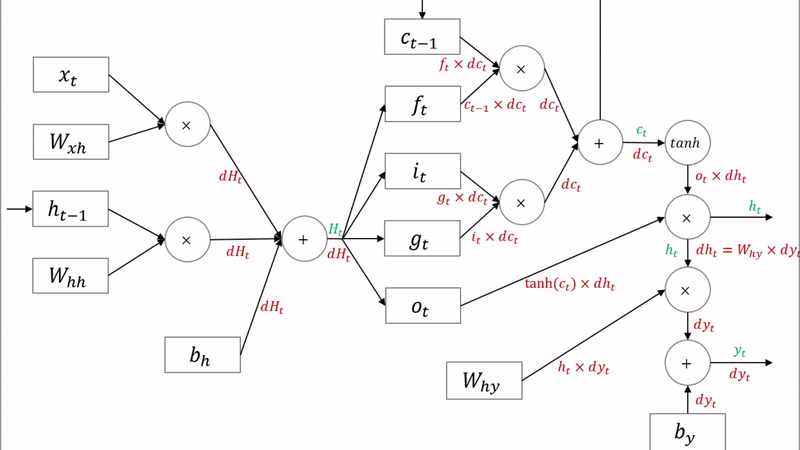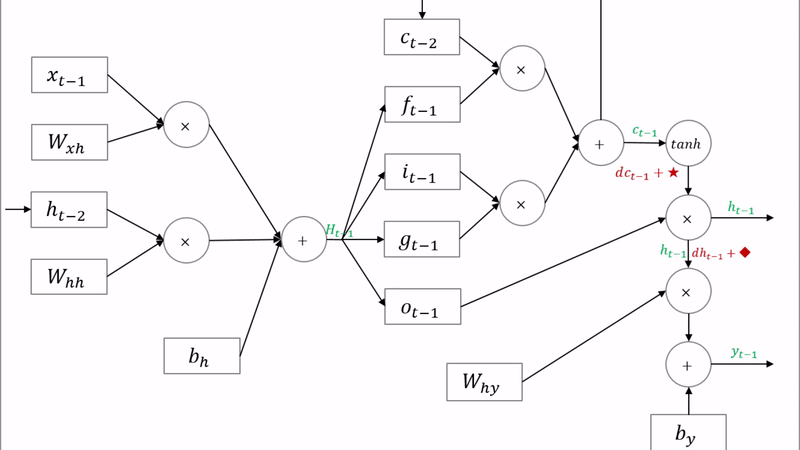
LSTM
LSTM은 위와 같은 문제들을 해결하기 위해 Memory cell(수학적은 잊는 것)을 도입하였다. 과거의 정보에 몇 %만 기억할지 설정한다. 언어 모델 뿐만 아니라 신경망을 활용한 시계열 알고리즘에는 대부분 LSTM을 사용한다. LSTM에는 3개의 gate를 갖고 있다.

기울기 소실 문제를 해결하기 위해 3가지 게이트를 추가되었다.
- forget gate (ft): 얼마나 과거 정보를 유지할 지 결정한다.
- input gate (it) : 얼만큼 새로운 정보를 활용할 지 결정한다.
- output gate (ot) : 얼만큼 계산한 정보를 넘겨줄지 결정한다.
cell-state는 역전파 과정에서 활성화 함수를 거치지 않아 정보 손실이 없기 때문에 뒷쪽 시퀀스의 정보에 비중을 결정할 수 있으면서 동시에 앞쪽 시퀀스의 정보를 완전히 잃지 않을 수 있다.
GRU (Gated Recurrent Unit)
LSTM의 간소화 버전이다.
- LSTM에서 있었던 cell-state는 더 이상 없다.
- 새로운 벡터 ht는 cell-state 벡터 ct 와 hidden-state 벡터 ht를 담고 있다.
- forget, input gate는 Gate zt가 모두 제어한다. 즉, zt=1 이면 forget 게이트가, zt=0이면 input 게이트가 열린다.
- output 게이트가 없다. 게이트 rt는 이전 상태의 어느 부분이 출력될지를 결정한다.
- GRU는 2개의 gate를 갖고 있다. GRU에서 하나의 gate가 LSTM의 input gate, forget gate의 역할을 모두 수행한다.
- GRU가 LSTM보다 학습해야 할 파라미터의 수가 적다.

RNN 구조에 Attention 적용하기
기울기 소실로부터 나타나는 장기 의존성 문제를 해결하기 위해 나온 것이 LSTM, GRU 이다. 하지만 이 둘은 고정 길이의 hidden-state 벡터에 모든 단어의 의미를 담아야한다. 이 문제를 해결하기 위해 고안된 것이 Attention이다. 모든 time step 에서 생성된 hidden-state를 간직했다가 디코더에게 모두 넘겨준다.
즉, 어텐션은 인코더에 입력된 문장의 단어와 디코더가 생성하려는 단어가 연관된 정도를 나타내는 가중치이다. 어텐션을 사용하면 각 time-step 마다 출력할 단어가 인코더의 어떤 단어 정보와 연관되어 있는지 알 수 있으며, 이를 통해 장기 의존성 문제를 해결 할 수 있다.
'AI 부트캠프' 카테고리의 다른 글
[n425] 자연어 처리 요약 (0) 2021.12.30 [n424] Transformer (0) 2021.12.29 [n422] Distributed Representation (0) 2021.12.27 [n421] Count-based Representation (0) 2021.12.24 [n414] 신경망 기본 개념 요약 (0) 2021.12.22