-
[n413] Learning rate, 가중치 초기화, 과적합 방지AI 부트캠프 2021. 12. 21. 10:29
더 나은 신경망 학습을 위한 방법들
- 학습률(Learning rate)
- 가중치 초기화(Weight Initialization) & Regularization
학습률 감소 및 계획법 (Learning rate decay / Scheduling)
학습률 (Learning rate)
학습률은 보폭을 결정한다. 즉, 얼만큼 이동할지를 조정하는 하이퍼 파라미터로, 경사 하강법에 어느 정도로 기울기 값을 적용할지 결정한다. 학습률이 크면 보폭이 크므로, 성큼 성큼 이동하고, 작으면 조금씩만 이동하는 개념이다.
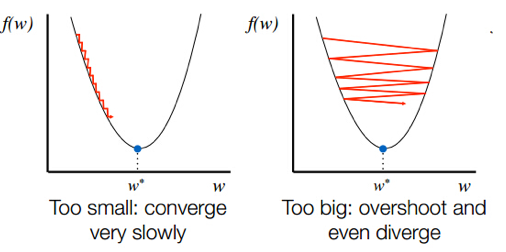
학습률이 너무 작거나 클 때는 다음과 같다. 왼쪽 그림과 같이 학습률이 작으면, 최적점에 이르기까지 매우 오래 걸린다. 학습률이 너무 크면, 발산하면서 모델이 최적값을 찾을 수 없을 수 있다.
학습률 감소(Learning rate Decay)
학습률 감소는 Adagrad, RMSprop, Adam 과 같은 옵티마이저에 이미 구현되어 있다. 해당 옵티마티저의 하이퍼파라미터를 조정하면 감소 정도를 변화시킬 수 있다. 여기서 lr이 learning rate이다.
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89) , loss='sparse_categorical_crossentropy' , metrics=['accuracy'])학습률 계획법(Learning rate Scheduling)
학습률 계획법은 학습률을 유동적으로 사용할 수 있게 설정하는 것이다. 일반적으로 warm-up step을 준 뒤 천천히 내려가도록 설정한다.
학습률 계획은 다음과 같이 .experimental 내부의 함수를 사용한다.
first_decay_steps = 1000 initial_learning_rate = 0.01 lr_decayed_fn = ( tf.keras.experimental.CosineDecayRestarts( initial_learning_rate, first_decay_steps)) model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_decayed_fn) , loss='sparse_categorical_crossentropy' , metrics=['accuracy'])가중치 초기화 (Weight Initialization)
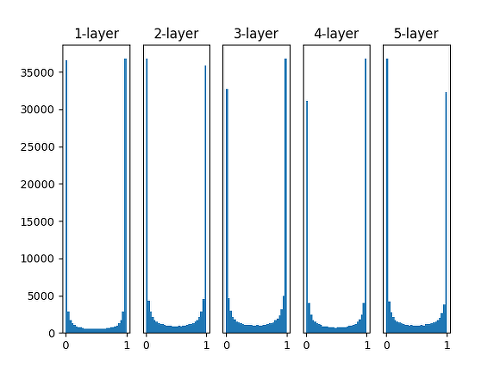
표준편차를 1인 정규분포로 가중치를 초기화 할 때 각 층의 활성화 값 분포
가중치를 정규 분포로 초기화 할 때 0과 1에 활성화 값이 대부분 위치하는 것을 확인 할 수 있다. 표준편차를 1인 정규분포로 가중치를 초기화한다는 것은 표준편차가 1인 정규분포를 따르는 랜덤 값으로 가중치를 초기화 한다는 것을 의미한다. 하지만, 학습이 제대로 수행되지 않는 경우도 있으므로 실제로는 잘 사용되지 않는다.
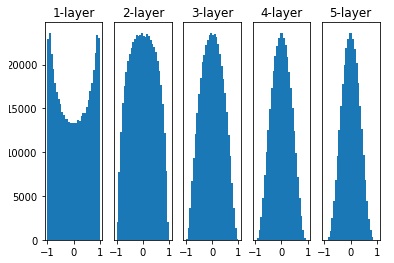
Xavier 초기화를 해주었을 때의 활성화 값의 분포
Xavier 초기화(Xavier initialization)는 위의 경우에서 생기는 문제점을 보완하기 위해 등장하였다. Xavier Initialization은 이전 층의 노드 개수 n이 있을 때, 현재 레이어의 가중치를 표준편차가 1/√n인 정규분포로 초기화 하는 것을 의미한다.
하지만, Xavier Initialization는 활성화 함수가 시그모이드(Sigmoid)일 때는 잘 동작하지만 ReLU 함수 일 때는 고르지 못하게 되는 문제가 있다.
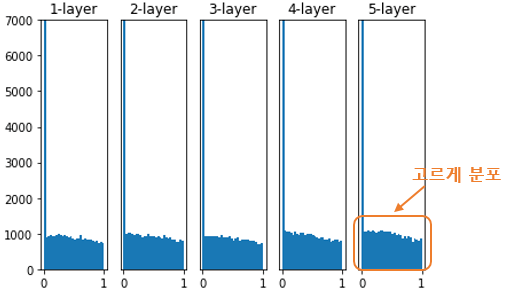
He 초기화를 했을 때 활성화 값의 분포
Xavier Initialization의 문제를 해결하기 위해 He 초기화(He initialization)가 등장했다. 이전 층의 노드 개수 n이 있을 때, 현재 레이어의 가중치를 표준편차가 2√n인 정규분포로 초기화 한다.
Activation function에 따른 초기값 추천
- Sigmoid 함수 일 때는 Xavier Initialization 추천.
- ReLU 함수 일 때는 He 초기화 추천.
과적합 (Overfitting) 방지
머신러닝에서 모델이 복잡해지면 과적합 문제가 발생하는 경향이 있다. 이를 방지하기 위한 방법이 다음과 같다.
Weight Decay (가중치 감소)
대부분의 경우 과적합은 가중치의 값이 클 때 발생한다. 그러므로 가중치가 너무 커지지 않도록 설정한다.
L1 Regularization(Lasso), L2 Regularization (Ridge)로 나뉘며 각 방법에 따라 손실 함수는 아래와 같다.
Dense(64, kernel_regularizer=regularizers.l2(0.01), activity_regularizer=regularizers.l1(0.01))Dropout (드롭아웃)
매 iteration 마다 노드의 일부를 의도적으로 사용하지 않는다. 즉, 특정 가중치가 계속 학습되는 것을 막기 위해 매번 다른 노드로 학습하면서 과적합을 방지한다.
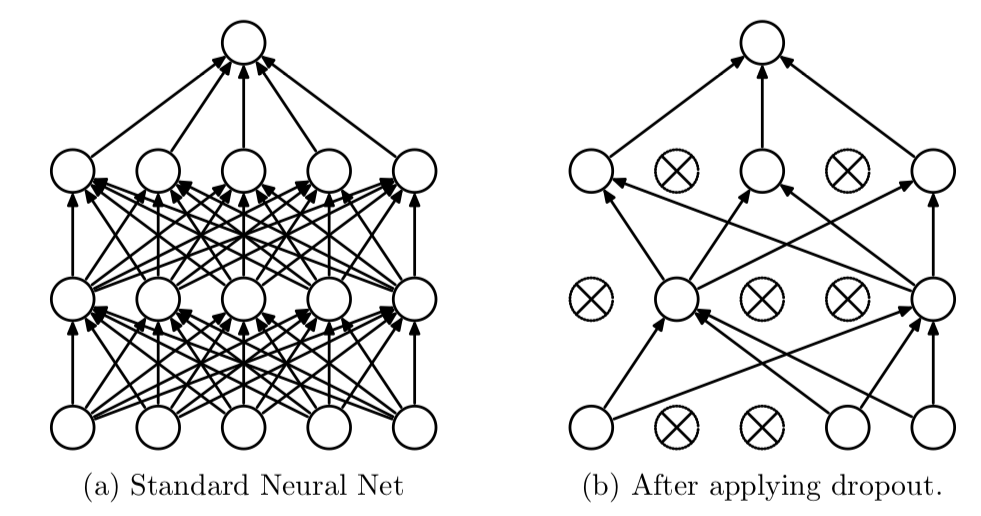
64개 노드 중 0.5비율 즉 32개는 쓰지 않겠다는 의미이다.
Dense(64, kernel_regularizer=regularizers.l2(0.01), activity_regularizer=regularizers.l1(0.01)) Dropout(0.5)Early Stopping (조기종료)
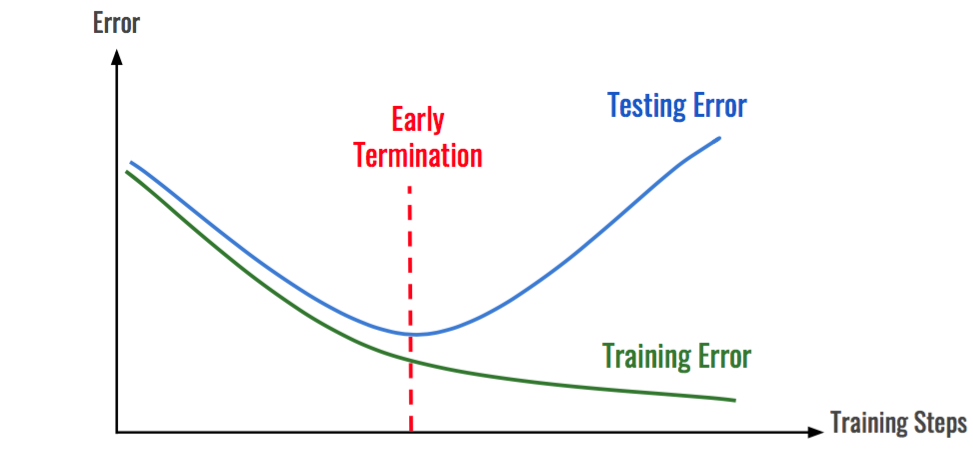
아래 그래프와 같이 학습 데이터에 대한 손실을 줄어들지만 검증 데이터셋에 대한 손실은 증가한다면 학습을 종료하도록 설정한다.
'AI 부트캠프' 카테고리의 다른 글
[n414] 신경망 기본 개념 요약 (0) 2021.12.22 [n414] 하이퍼 파라미터 튜닝 (0) 2021.12.22 [n412] 역전파, 경사하강법, 옵티마이저 (0) 2021.12.20 [n411] Neural Networks (0) 2021.12.17 [n341] Project - Troubleshooting (0) 2021.12.08