-
[논문] ViT_An Image is worth 16x16 words: Transformers for Image Recognition at scale컴퓨터 비전 2022. 4. 26. 17:22
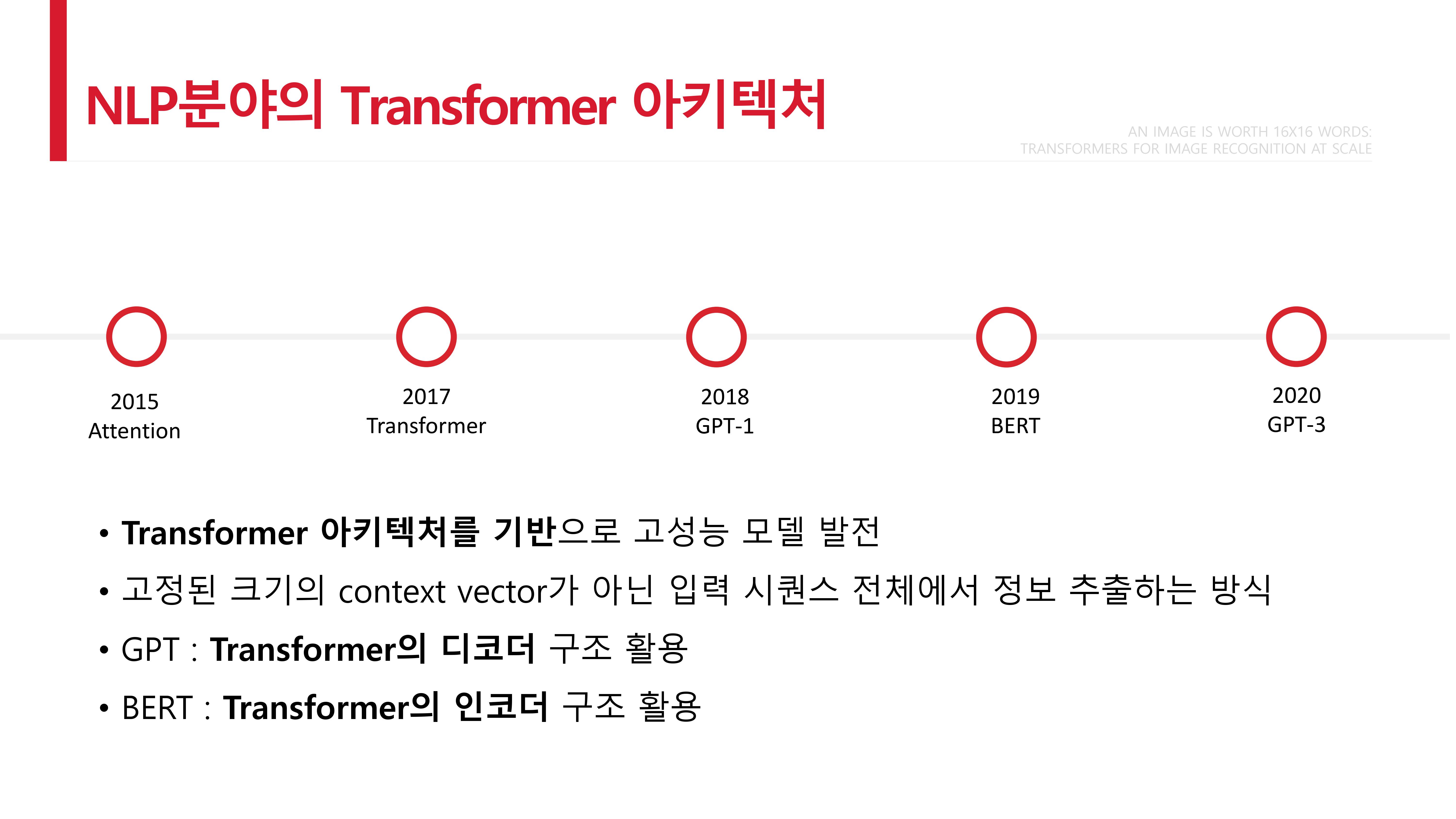
Vision Transformer 분야가 많은 관심을 받고 있습니다. NLP에서만 주로 쓰이던 transformer 구조를 Vision 분야에 적용해서 높은 성능을 구현한 논문입니다.
논문 링크는 다음과 같습니다.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
요약을 열심히 해봤는데 혹시 잘못된 부분 있으면 댓글이나 메일 (dawun.han@gmail.com)부탁드립니다.
감사합니다.











'컴퓨터 비전' 카테고리의 다른 글
[논문] Video Super-Resolution Based on Deep learning: A Comprehensive Survey (0) 2023.08.18 [논문] Object Detection in 20 Years - A Survey (0) 2022.04.08
